Scenario: Users have to access and download files from a S3 bucket but not upload or change the contents of the same.
We can address the requirement by following official documented steps here
To make your bucket publicly readable, you must disable block public access settings for the bucket and write a bucket policy that grants public read access. If your bucket contains objects that are not owned by the bucket owner, you might also need to add an object access control list (ACL) that grants everyone read access.
But for my use case the bucket cannot be made public, users should be able to browse the files in S3 as good as any person with AWS login credentials with CLI or Python while retaining the read only access.
Hence, Jupyter Notebooks comes to my rescue to build a solution as described in this post.
- Preparing EC2 to host Jupyter
- Create S3 read only instance role
- Create default Notebook
- Download Files
- Conclusion
Preparing EC2 to host Jupyter
Create an EC2 to serve as a Bastion host with
- Jupyter Notebook
- AWS CLI
- Python Boto3
This can be achieved by steps mentioned here
At the end, we have a Jupyter notebook URL generated which users can access from any browser.
Create S3 read only instance role
Next create EC2 instance role with read only access policy for the S3 as below.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": ["arn:aws:s3:::my_bucket",
"arn:aws:s3:::my_bucket/*"]
}
]
}Attach this role to the EC2 and we are good to access all the S3 files from it.But wait we are not going to give EC2 access directly to the user.
Create default Notebook
Jupyter URL generated in the first step now act as a webservice running on our Bastion Ec2 and allows required S3 access to the users.
Now, to make the work easy for non-technical user.We can create a notebook with all the required S3 commands and save it in the default directory
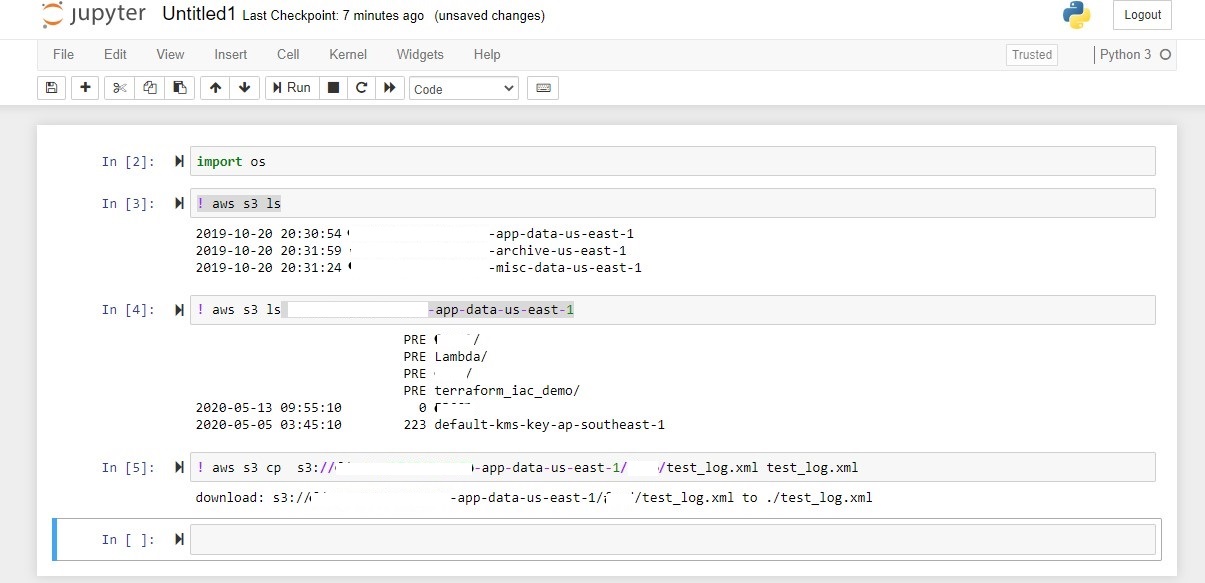
The notebook has Commands to
- Browse files in S3.
- Copy files from S3 to temp directory on EC2 machine.
Download Files
Once we have followed all the steps, we should see our required file from the S3 available to download in temp directory.
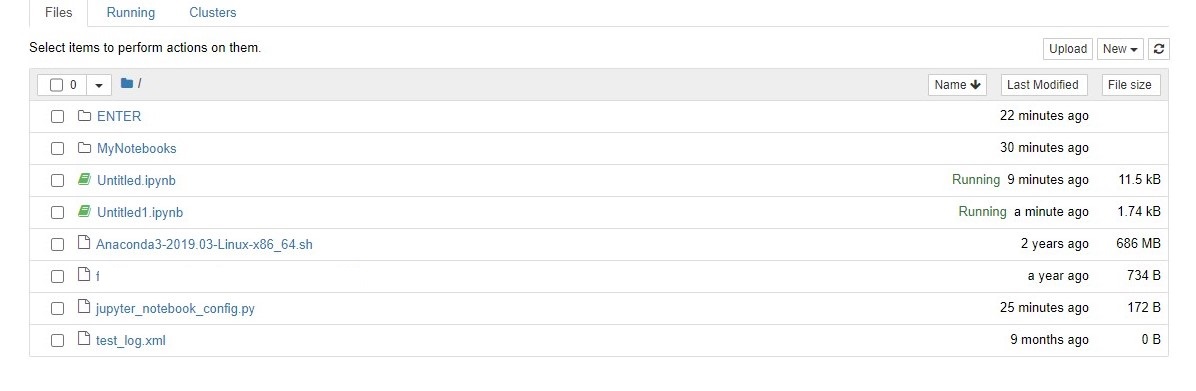
Select the file, click download and we are good to use the file.
Conclusion
There might be better ways to achieve the same result and this could have downside of user misusing the EC2 machine.But at the end,it is quick and easiest solution I could put together and get working.
Also, Jupyter Hub can be used instead of notebook for more granular control and scaling for multiple users.